2023年2月,美国前国务卿基辛格与谷歌前首席执行官施密特、麻省理工学院教授丹·胡腾洛赫共同发表了一篇文章,名为《ChatGPT预示着一场智力革命》(ChatGPT Heralds an Intellectual Revolution)。
基辛格提出,自印刷术发明数百年之后,生成式大语言模型将再一次改变人类的认知过程。“OpenAI开发的ChatGPT现在能够与人类交流。随着它们的能力变得更广泛,它们将重新定义人类知识,加速我们现实构造的变化,并重组政治和社会。”
一般而言,信息系统的拐点便是将信息的生产和获取成本从边际成本转向固定成本。
举一个简单的例子,过去找到某个目的地需要花几块钱买份地图,然后在地图上慢慢寻觅,而现在用高德等APP搜索,需要的时间不到300毫秒,高德花费的成本不到一分钱,而这是由于高德使用了大量的测绘等固定成本做到的。即从每次消费者都要付很多,变成了高德一次性付很多。
而大模型带来的关键转变也在于此,将人的成本从边际成本变为固定成本,过去的律师、医生等专业性的工作均可由其完成。
正因如此,自ChatGPT发布后,上线仅5天就吸引了100万名用户,两个月后,月活跃用户就已经达到1亿人次,成为历史上用户数量增长最快的消费级应用。要知道,TikTok经过大约9个月的时间才达到这一量级,而Instagram则用了两年半。
01
百模大战
巨大的蛋糕谁都想来分上一块。
据朋湖网不完全统计,我国目前已有超过100家机构发布了自己的AI大模型,其中通用大模型就有超过20个。
8月31日,国内首批八家大模型通过《生成式人工智能服务管理暂行办法》备案,百度、智谱、百川、字节、商汤、中科院(紫东太初)、MiniMax、上海人工智能实验室这八家机构的大模型正式上线面向公众提供服务。
然而,大模型投入极大,极其耗费资源。英伟达曾透露,训练一次1750亿参数的GPT-3需要34天,使用1024张A100 GPU芯片,单次训练成本高达1200万美元。
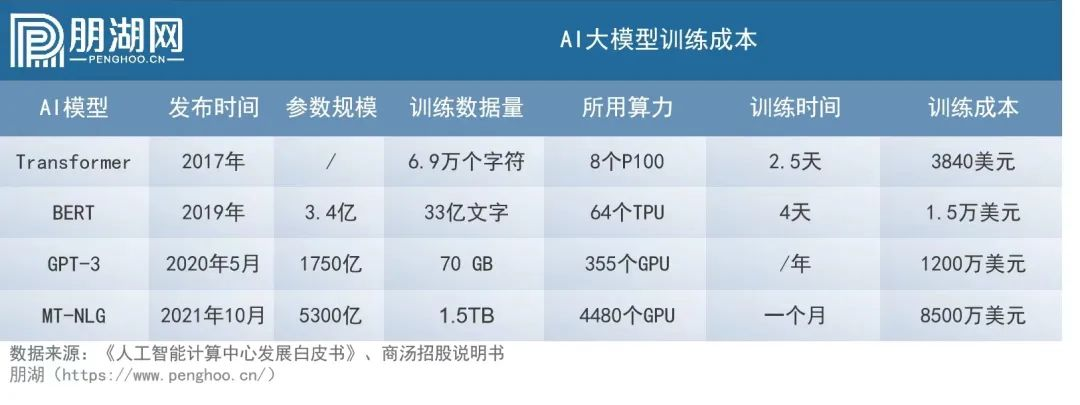
“超过千亿(参数)级别的大模型,训练需要投入的人力、电力、网络支出等投入,一年至少5000万美金到1亿美金。”昆仑万维CEO方汉认为。
微软甚至为了训练大模型,建成一台排名世界前五的超级计算机。
以上种种统统证明了,通用大模型拥有极高的准入门槛,早已不是入门者的游戏。然而,改变世界的机会没有人能视而不见,因此,国内几乎所有知名的互联网公司均有大模型方向的布局。
2010年,以拉手网、窝窝团、美团等为代表的“千团大战”如火如荼,虽然活到如今的只剩一家,但这场竞争客观上的确为消费者普及了移动互联网。如今的大模型同样如此,已是业内共识的是,通用大模型未来可能只有两三家,甚至可能只有一家。
而如何才能活到最后,在数据与模型之外,应用才是关键所在。
02
商业化困境
早在2016年,当DeepMind研发的AlphaGo击败李世石后,其宣布与英国国家卫生服务局,以及Moorfields眼科医院、伦敦大学医院等机构展开AI医疗诊断算法的合作,包括IBM旗下的Watson Health也趁着这股势头加快了拓展的脚步。
自此,人工智能迅速成为了资本市场最为性感的故事,甚至一度到某个公司发个关于AI合作的通稿就能看到股票的拉升。
泡沫破灭的同样很快。
2017年,在AI界顶级的神经信息处理系统大会(NIPS)上,阿里·拉希米将当时快速发展的机器学习比作炼金术,即方法虽然有不错的效果,但缺乏严谨完备可验证的理论知识,这直接戳破了当时AI存在的最大问题。
2018年,Watson Health被曝出内部文件,显示其肿瘤诊断算法经常给出不准确的、与美国国家治疗指南相悖的建议。例如,对于一名被诊断患有肺癌,同时伴有严重出血症状的患者,Watson Health给出的建议是接受化疗并使用药物贝伐珠单抗(Bevacizumab),然而该药物可能导致“严重或致命的出血”,建议不要给患有严重出血的患者服用。
2019年,IBM停止了沃森人工智能药物研发工具的开发和销售,理由是销售表现令人失望。
这揭示了人工智能的行业落地最大的问题——业务难以复制,模型不可泛化。
对如今的大模型而言依然如此。
一方面,通用大模型用于训练的信息大部分属于网络信息,有相当一部分存在错误,同时专业知识与行业数据的积累较为浅薄,导致数据的“噪音”过大,难以满足专业要求高、容错率低的产业场景需求,毕竟我们对于大模型的希望肯定不止于“写写诗、聊聊天”而已。
另一方面,行业场景有丰富的know-how诉求,对数据的“投喂”要讲究行业特殊性,如在生产管理中,要将原料特性、排产规则、资源分配规则等特定数据“喂养”给大模型,才能实现替代操作员类似的效果。
03
生态机会
为了更好的实现商业化,大模型企业均在不遗余力地推进生态化建设。
2022年,阿里云在国内首倡MaaS(Model as a Service,模型即服务)理念,提出以AI模型为核心的开发范式,并搭建了一套以AI模型为核心的云计算技术和服务架构,并将其全部向大模型初创企业和开发者开放。
“阿里云将把促进中国大模型生态的繁荣作为首要目标”, 阿里云首席技术官周靖人说道。
5月,百度宣布设立规模为10亿元的“百度文心投资基金”,重点投资孵化大模型领域的优质创业企业。资料显示,百度千帆大模型如今月活企业近万家,覆盖金融、制造、能源、政务、交通等行业的400多个业务场景。
多名AI行业的从业者均向朋湖网表达过:“对于应用场景而言,将大模型与行业小模型结合起来将会产生巨大的价值。”大模型可以带来非专业信息的生成以及更舒适的人机交互,而小模型可以带来更为专业的行业信息。
应用层的商业价值同样巨大。举例而言,Monica是一款基于Google浏览器的Chrome扩展插件,它可以帮助用户撰写文案、智能搜索。Google的数据显示,其收入在每年6000万美金左右,但其团队也才仅仅11人。
百度创始人李彦宏也表达了类似的观点,“对于创业者来说,卷大模型没有意义,卷应用机会更大。移动互联网时代操作系统只有安卓和iOS,但特别成功的应用却很多,只有在大模型基础上产生足够多的AI原生应用,才是一个健康的生态环境。”
04
开源之争
与操作系统类似,在大模型生态中,闭源与开源之争也在愈演愈烈。前者的代表是GPT、百度千川等,而后者的代表则是Meta旗下的LLaMA、阿里通义千问等。
与闭源相比,开源大模型可以降低模型的二次开发门槛,有助于各个领域的广泛应用和普及。更重要的是,大模型开源后可以获得社会的加持,在开发者社区驱动的创新和改进下,可能获得更好的发展。
2月,在Meta宣布开源LLaMA后,一个月内就涌现了许多扩展版本,影响较大的有斯坦福大学开发的Alpaca,以及来自加州大学伯克利分校、卡内基梅隆大学等开发的Vicuna。
谷歌工程师Luke Sernau甚至发文称:“除非谷歌和OpenAI改变态度,选择和开源社区合作,否则将被后者替代。”
7 月 19 日,Llama升级到Llama2。后者在 2 万亿的 token 上进行训练,训练数据增加了 40%,各项外部基准测试中皆优于其他开源语言模型。
“Llama2 出现之后,受打击最大的应该就是 OpenAI,更多的公司会开始直接基于 Llama2 进行商业化开发,而不再购买它们的 API。”猎豹移动董事长傅盛表示。
然而,当下在模型层面上,GPT-4依然遥遥领先,据业内人士判断,短期内这一领先优势很难被颠覆。
而闭源的支持者们也有其道理所在。百度集团执行副总裁沈抖认为基础模型的升级需要有效的反馈回路,开源模型发展的最大痛点在于反馈路径不理想,可能会"走弯路", 事倍功半。
05
写到最后
从2006年亚马逊推出弹性计算云EC2算起,云计算已走过十余年时光。
从 AWS 起步时的牛刀小试,到如今已成长为一个巨大的生态体系,生长出了一大批如Salesforce、Shopify等的头部企业。
如今,我们又站在了人工智能原生产品的新起点,大模型也将在这次巨变中发挥重要的影响力。

百度昆仑芯启动赴港上市,目标估值500亿美金

智平方完成50亿融资,估值破200亿

上市前两次分红!量子科技独角兽「频准激光」科创板IPO注册生效

